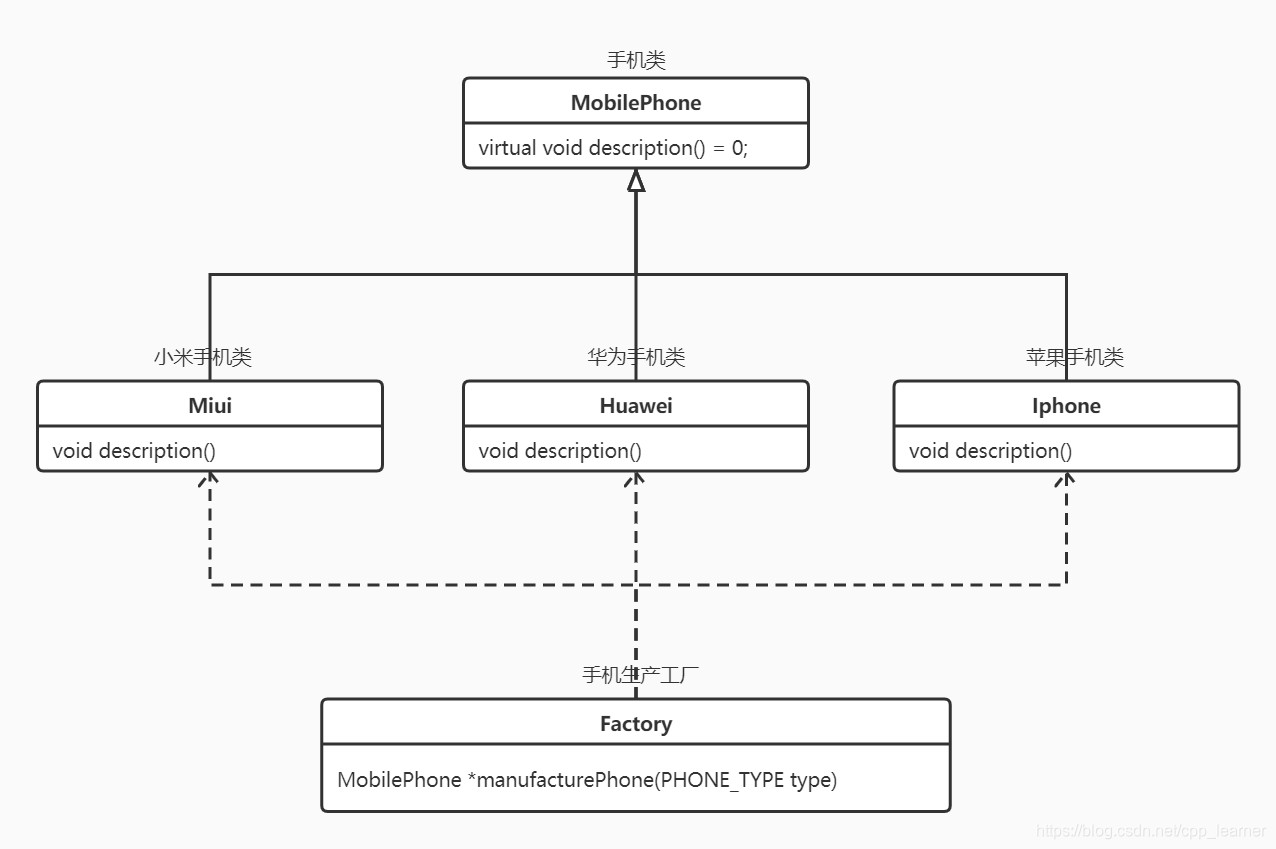
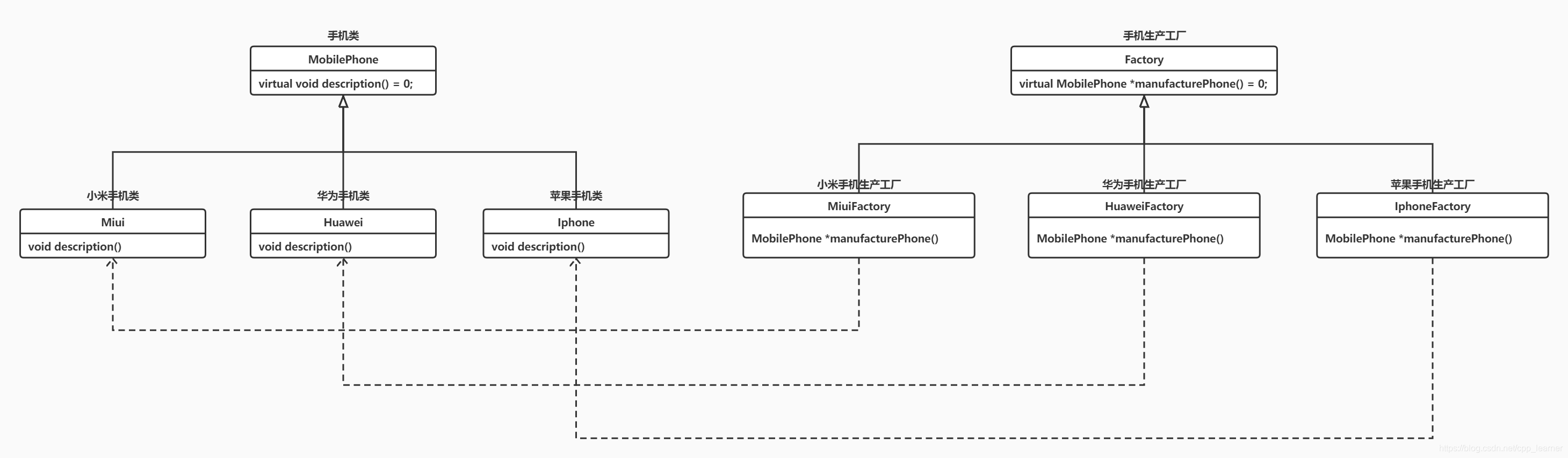
取自《Effective C++:改善程序与设计的55个具体做法》中文版第三版
二、构造/析构/赋值运算 05:了解C++默默编写并调用哪些函数 对于创建一个空类,当C++处理过后,如果没有声明,则编译器会为它声明一个 copy 构造函数、一个 copy assignment 操作符和一个析构函数,此外还有 default 构造函数。因此,对于 class Empty { }; ,等同于如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Empty { public : Empty () { ... } Empty (const Empty& rhs) { ... } ~Empty () { ... } Empty& operator =(const Empty& rhs) { ... } }; Empty e1; Empty e2 (e1) ; e2 = e1;
如果类中声明了一个构造函数,则编译器不再为它创建 default 构造函数。
编译器产生的 copy assignment 操作符,一般而言只有当生出的代码合法且有适当机会证明其意义,才会去创建它,否则会拒绝创建。见下实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <class T >class NameObject {public : NameObject (std::string& name, const T& value); ... private : std::string& nameValue; const T objectValue; }; std::string newDog ("Persephone" ) ;std::string oldDog ("Satch" ) ;NamedObject<int > p (newDog, 2 ) ;NamedObject<int > s (oldDog, 2 ) ;p = s;
对于 p = s; 的赋值操作,C++的响应是拒绝编译,其一是C++并不允许 “让 reference 改指向不同对象”;再者就是更改 const 成员是不合法的,编译器不知道如何处理;因此,这就需要自己去定义 copy assignment 操作符了。此外,如果一个基类的 copy assignment 操作符声明为 private,编译器就会拒绝生成子类的 copy assignment 操作符,原因则是默认生成的函数无权调用二点权限问题。
对于 “C++并不允许 ‘让 reference 改指向不同对象’ ” 的解释,我所理解的就是,假设程序可以运行的情况下, ‘p = s’ 希望得到的是 p.nameValue 去引用 oldDog,而因为这一条机制的原因,实际得到的为:p.nameValue 引用的对象并没有变更,变更的是 newDog = “Satch”,尽管输出看起来一致,但实现机制不一样。
编译器可以暗自为 class 创建 default 构造函数、copy 构造函数、copy assignment 操作符,以及析构函数。
06:若不想使用编译器自动生成的函数,就该明确拒绝 对于一个 class,如果不希望其支持某一个功能,只要不声明对应函数即可,但对于系统会自动生成的 copy 构造函数、copy assignment 操作符,则可以采用将其声明为 private 的方式去阻止外部调用,而对于内部调用的情况,可以通过不去定义函数来避免调用。
1 2 3 4 5 6 7 8 class HomeForSale {public : ... private : ... HomeForSale (const HomeForSale&); HomeForSale& operator =(const HomeForSale&); };
对于上述定义,如果尝试拷贝 HomeForSale 对象,则编译器就会提示错误信息。 因为这个机制,可以单独设计一个 base class,然后去继承即可,如下示例:
1 2 3 4 5 6 7 8 9 10 11 12 class Uncopyable {protected : Uncopyable () {} ~Uncopyable () {} private : Uncopyable (const Uncopyable&); Uncopyable& operator =(const Uncopyable&); }; class HomeForSale : private Uncopyable { ... };
为驳回编译器自动提供的机能,可将相应的成员函数声明为 private 并且不予实现。使用像 Uncopyable 这样的 base class 也是一种做法。
07:为多态基类声明 virtual 析构函数 1 2 3 4 5 6 7 8 9 class TimeKeeper {public : TimeKeeper (); ~TimeKeeper (); ... }; class AtomicClock : public TimeKeeper { ... };class WaterClock : public TimeKeeper { ... };
对于上诉计时代码,若设计工厂函数,返回指针指向一个计时对象,如下:
1 2 3 TimeKeeper* ptk = getTimeKeeper (); ... delete ptk;
然而,getTimeKeeper() 返回的是一个派生类对象(如 AtomicClock),而对象经由基类释放,因C++规则:当派生类对象经由基类指针删除,而基类带有非虚析构函数,其结果未有定义–实际执行导致该对象的派生类成分可能未被销毁,即派生类的析构函数未被执行,从而导致资源泄露等问题。解决方式:给基类一个虚析构函数:
1 2 3 4 5 6 class TimeKeeper {public : TimeKeeper (); virtual ~TimeKeeper (); ... };
对于不被用于继承的类,则不需要设计虚析构函数。虚函数在运行期间决定被调用是由一个 vptr 指针指出,因此如果一个类含有虚函数,其对象的占用空间也相应的会增加大小,可能会带来不必要的麻烦。
由于很多基类的设计目的并不是用于多态用途,如标准 string 和 STL容器等,不具有虚析构函数,因此应尽量避免用于继承。
如果在一个需要设计抽象类的场合却没有纯虚函数的情况下,可以通过声明纯虚析构函数实现,相应的也需要为这个纯虚析构函数添加定义,如下示例:
1 2 3 4 5 6 class AWOV {public : virtual ~AWOV () {} = 0 ; } AWOV::~AWOV () {}
polymorphic(带多态性质的)基类应该声明一个虚析构函数;如果类带有任何虚函数,也应该声明一个虚析构函数。
08:别让异常逃离析构函数 C++ 并不禁止析构函数吐出异常,但也不鼓励这样做。比如,对于一个容器 vector 含有多个 Wigdets 对象元素,析构第一个元素期间,有个异常被抛出,此时其他元素仍会被销毁,若第二个析构又抛出异常,则会存在两个异常,对于C++而言,程序若不是结束执行就是导致不明确行为。
如果析构函数必须执行一个动作,而这个动作可能会在失败时抛出异常,怎么办呢?通常有两种方法:
如果抛出异常就结束程序,通常通过 abort 完成
1 2 3 4 5 6 7 8 DBConn::~DBConn () { try { db.close (); } catch (...) { 制作运转记录,记下对 close 的调用失败; std::abort (); } }
吞下因调用 close 而发生的异常
1 2 3 4 5 6 7 DBConn::~DBConn () { try { db.close (); } catch (...) { 制作运转记录,记下对 close 的调用失败; } }
一个更好的策略是提供一个 close 函数,将调用 close 的责任从 DBConn 析构函数转移到客户手上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class DBConn {public : ... void close () { db.close (); closed = true ; } ~DBConn () { if (~closed) { try { db.close (); } catch (...) { 制作运转记录,记下对 close 的调用失败; ... } } } }
析构函数绝对不要吐出异常。如果一个析构函数调用的函数可能吐出异常,应捕捉异常后吞下或者结束程序。
09:绝不在构造和析构过程中调用 virtual 函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Transaction {public : Transaction (); virtual void logTransaction () const 0 ; ... } Transaction::Transaction () { ... logTransaction (); } class BuyTransaction : public Transaction {public : virtual void logTransaction () const ... };
对于以上示例,如果此时调用 BuyTransaction b;,首先 Transaction 构造函数会被最先调用,而此时 BuyTransaction 的构造函数还未被调用,这时候调用的 logTransaction 函数是 Transaction 内部的版本,而 Transaction 内部版本为纯虚函数,因此程序无法正常执行。唯一避免该问题的做法是:确定构造函数和析构函数都没有调用 virtual 函数。
如何确保每一次 Transaction 继承体系的对象被创建时都会调用 logTransaction 函数呢,一种做法是将该函数改为非虚函数。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Transaction {public : explicit Transaction (const std::string& logInfo) void logTransaction (const std::string& logInfo) const ... } Transaction::Transaction (const std::string& logInfo) { ... logTransaction (logInfo); } class BuyTransaction : public Transaction {public : BuyTransaction (parameters): Transaction (createLogString (parameters)) {...} ... private : static std::string createLogString (parameters) };
此种方式将 “无法使用virtual函数从基类向下调用” 替换为 “令子类将必要的构造信息向上传递至基类”。
在构造和析构期间不要调用虚函数,因为这类调用不会下降至子类。
10:令 operator= 返回一个 reference to *this 1 2 int x, y, z;x = y = z = 15 ;
为了实现类的连锁复制,赋值操作符必须返回一个 reference 指向操作符的左侧实参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Widget {public : ... Widget& operator =(const Widget& ths) { ... return *this ; } Widget& operator =(int ths) { ... return *this ; } }
令赋值操作符返回一个 reference to *this。
11:在 operator= 中处理 “自我赋值” 1 2 3 w = w; a[i] = a[j]; *px = *py;
如果会运用对象来管理资源,且确定“资源管理对象”在复制时正确,则“自我赋值为安全的”;但是如果自行管理资源,可能会出现“复制前释放资源”的问题,举例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Bitmap { ... };class Widget { ... private : Bitmap* pb; }; Widget& Widget::operator =(const Widget& rhs) { delete pb; pb = new Bitmap (*rhs.pb); return *this ; }
这里存在的安全性问题为若 *this 和 rhs 指的是同一个对象,如在出现一个指针指向一个被销毁的对象的情况。传统的一个解决做法为在最前面添加一个“证同测试”检验:
1 if (this == &rhs) return *this ;
但是该方法仍存在一个隐患:假设 new Bitmap 异常,那么始终会有一个指针指向一个被删除的对象。那么从“异常安全性”的方面考虑,可得到方案如下–复制后删除:
1 2 3 4 5 6 7 Widget& Widget::operator =(const Widget& rhs) { Bitmap* pOrig = pb; pb = new Bitmap (*rhs.pb); delete pOrig; return *this ; }
该方案即使 new Bitmap 异常,pb 也会保持原样。另外一种方案是 copy and swap 技术。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Widget { ... void swap (Widget& rhs) ... }; Widget& Widget::operator =(const Widget& rhs) { Widget temp (rhs); swap (temp); return *this ; }
确保当对象自我赋值时 operator= 有良好行为。
12:复制对象时勿忘其每一个成分 如果设计类没有使用系统自动生成的拷贝函数,而是设计自己的拷贝函数,那么出错时编译器有可能不会提示。如果拷贝函数中忘记写全成员变量,那么其会保持不变。
拷贝函数应该确保复制“对象类的所有成员变量”及“所有基类成分”。